|
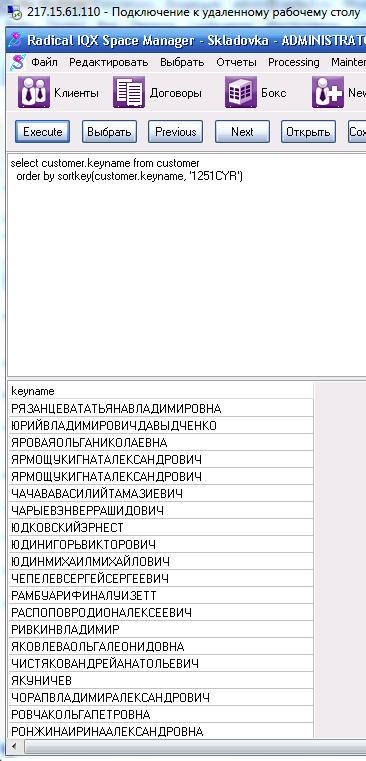
Hi, I have a client in Russia using our software in Cyrillic and they are getting what I would describe as "odd" ordering of alphanumeric lists. When displaying a list of names the order appears alomost random in that there will be a number of A's then a number of B's then again some A's, Some B's, Some C's, Some Z's then some A's again. For example if it was in English they get: Aberthforth, Brian It might start off looking OK but then fails. I have a nice screenshot to show the example but I can't post this until I get to 100 points. If allowed I can post a link to the screenshot on our website if that helps. I have tried running simple queries in ISQL and get the same results: select customer.keyname from customer order by customer.keyname They are using SQL Anywhere 10 on Windows 7 and XP. It has been suggested that changing the collation of the database may help but this is totally new territory for me so thoughgt I would tap up the forum knowledge before I go down completely the wrong route. Thanks in advance. Alasdair Added for Alasdair: Character set 1252LATIN1, SQLA 10.0.1.3831
|
|
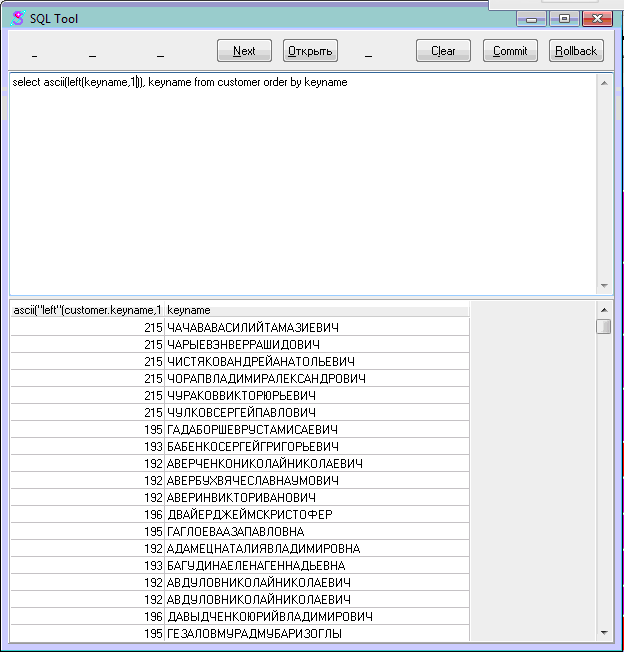
I'd say that it looks like someone has disabled (or otherwise bypassed) character set translation. This doesn't appear to be an NCHAR column since the first byte as reported in the "ascii()" column would not be reasonable lead bytes for Cyrillic characters. If it is a CHAR column, well, Cyrillic characters are not representable in CP1252. The characters 192 through 195 in CP1252 are accented forms of capital-A and are therefore considered equal: they will appear in an arbitrary order. -john. John, Thanks for the response. I believe you have hit the nail on the head. The simple solution to entering Cyrillic characters which were then translated into something else when saved to the database was to turn of Character Translation. I'm afraid to say we first did this back with a customer on ASA 8 and the suggestion came from Sybase. At the time I was stumped as to what was going on and phoned for support. I guess I didn't explain myself properly and they assumed I was on a database with the correct collation hence the suggestion. Anyway I'm off to lock myself in a room with no windows and research what the hell I might do to change the database collation back to the appropriate settings. Presumably a database unload and reload will not work! Anyone with any thoughts they would be gratefully appreciated. Thanks for all your help. Alasdair
(25 Aug '11, 10:33)
RADicalSYS
Replies hidden
2
I'm sorry if incorrect advice from Sybase led to the current situation. It should be pretty easy to change the collation. If you are only worried about this one database (rather than a large deployment) and the database truly does only contain CP1251 data then just do the following: 1) unload 2) Look at the reload.sql file and find the LOAD TABLE ... ENCODING 'windows-1252' statements. Change the 'windows-1252' to 'windows-1251' 3) create a new database with a 1251CYR collation 4) execute the reload.sql script If your schema (table names, procedure definitions, etc) contains Cyrillic characters, you may have other problems with those but you might be okay if your current locale is 1251 when you execute your script. I'm heading out of the office in an hour and won't be back until Monday. I'm sure others can step in if you encounter other problems in the meantime. Good luck!
(25 Aug '11, 10:52)
John Smirnios
OK, I'm getting a copy of the database and will try the unload and reload as above and let you know how it goes. Thanks again. Alasdair
(26 Aug '11, 07:16)
RADicalSYS
2
I eventually got the database and ahve tried the above. It does look fine to my eyes which is great news. I have sent it off to the customer to check and if they are happy I will do the same to their live database. Thanks very mcuh for your help. I'll report back.
(07 Sep '11, 07:05)
RADicalSYS
|
|
Wrong collation for Russian, should be 1251CYR instead. I agree that the wrong collation is being used; however, it also seems evident that charset translation is being bypassed. If it had not been bypassed, there would be lots of substitution characters in their data and (hopefully) they would have noticed that a different collation was needed. Even with the right collation, bypassing charset translation means that you'll end up with a good old mess once a client using a different charset performs operations on the same database. Well, substitution characters are a mess of their own but it takes work to bypass charset conversion and it was not a good solution to whatever problem prompted them to do so.
(25 Aug '11, 07:07)
John Smirnios
|
|
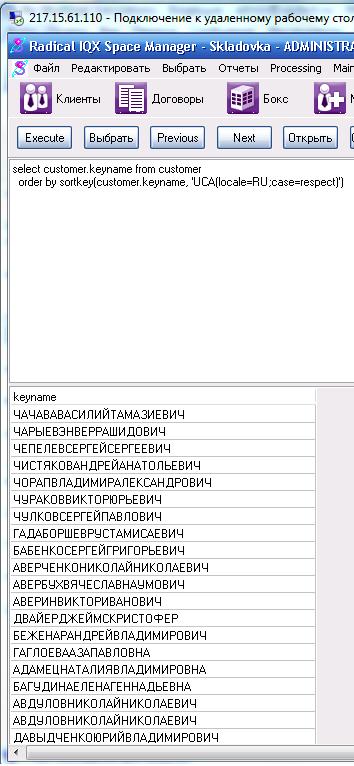
I'm no collation expert (but John is), but that seems like a collation problem. Whereas changing a database's collation is a serious task (you have to rebuild it) and should only be done when the consequences are understood, you might simply try with the COMPARE() or SORTKEY functions whether different collations yield more appropriate results. When using the UCA collation and using 10.0.1 or above, you might also have a look at the so-called collation tailoring options. Examples of such test queries: select customer.keyname from customer order by sortkey(customer.keyname, '1251CYR'); select customer.keyname from customer order by sortkey(customer.keyname, 'UCA(locale=RU;case=respect)'); 1
Thanks for the info Volker. Just had the client try the statements and we do get different results for the first one but the ordering is still up the spout! Justin may post the screenshots if he gets a chance and feels they're relevant. I had a look at the collation tailoring options but I don't see anything other than your second example above that might help. Thanks again.
(24 Aug '11, 13:00)
RADicalSYS
1
It certainly is a collation problem. I've seen similar stuff when database has been created with 866CYR (OEM/DOS) collation but actual data were in 1251 code page.
(25 Aug '11, 05:18)
Dmitri
1
Two things to note:
(25 Aug '11, 08:56)
Volker Barth
|
|
Images from Alasdair of the results of using SORTKEY in the ordering as suggested in Volker's post:
If my suspicions about bypassing charset conversion are correct, I don't expect sortkey used in this way to do any better since sortkey will implicitly convert charsets before computing the the key. In the first example above, we will convert data from what we think is CP1252 to CP1251 and, largely, every string will be full of substitution characters. You might try something like "order by sortkey( csconvert(customer.keyname,'utf8','cp1251'),'UCA(locale-RU)')" but that's just a crazy way of getting around the fundamental issue that the charset conversion is being bypassed in the original configuration which means that data stored in the database is being interpreted by the app as CP1251 and by the engine as CP1252.
(25 Aug '11, 07:00)
John Smirnios
Replies hidden
For some reason, I cannot edit my comment... Change my workaround to "order by sortkey( cast( csconvert(customer.keyname,'utf8','cp1251') as nchar),'UCA(locale-RU)')"
(25 Aug '11, 08:58)
John Smirnios
The reason might be that comments get "read-only" after exactly one hour - cf. this FAQ...
(25 Aug '11, 09:01)
Volker Barth
2
I agree with John that SORTKEY is not the right solution. It was implemented before we had NCHAR support and is intended to provide linguistically correct sorting beyond the capability of our SQL Anywhere collations such as 1251CYR. Depending on the requirements, 1251CYR is a perfectly good choice to store Cyrillic in CHAR columns and get reasonable sorting. If you want sorting like a phone book, consider using NCHAR columns and NCHAR collations (introduced in SA10). The difference in behaviour is most noticeable around letters that are considered related. I can't speak for Russian, but in Western languages an example is accented letters. SA collations consider all forms of the letter 'a' (with and without accents) to be equal and sort them as equal. Think of it as removing all of the accents, sorting, then putting the accents back in the result. I can see that 1251CYR has only a few "equal" letters, for example, 0x83, 0xb4 and 0xE3 are equal (variations of CYRILLIC SMALL LETTER GJE according to my references). Using NCHAR collations, you get phonebook-style sorting, where the base letter is used for initial comparison, then accents (and case) are considered as secondary attributes. See http://dcx.sybase.com/index.html#1201/en/dbadmin/natlang-s-7003956.html for more details.
(25 Aug '11, 11:43)
Steven McDowell
|